Of course, it is possible to perfectly build a consumer application without using Kafka Streams. For a real-time or dynamic package transfer, the code has to be sent and deployed at individual machines along with the prerequisites needed to execute the same. Kafka Streams is a popular client library used for processing and analyzing data present in Kafka. I think that the main thing that differentiate them is the ability to access store. In simple words, a stream is an unbounded sequence of events. Share your experience of using Kafka Streams in the comment section below. A stream typically refers to a general arrangement or sequence of records that are transmitted over systems.
It can also be used by logistics companies to build applications to track their shipments reliably, quickly, and in real-time.
Why did it take over 100 years for Britain to begin seriously colonising America? But we would need to manually implement the bunch of extra features given for free. You were then provided with a detailed guide on how to use Kafka Streams. Kafka Streams API can be used to simplify the Stream Processing procedure from various disparate topics. There are bulk tasks that are at a transient stage over different machines and need to be scheduled efficiently and uniformly. Explicitly specify SerDes when calling the corresponding API method, overriding the default. Teaching a 7yo responsibility for his choices. Besides, it uses threads to parallelize processing within an application instance. read one or more messages from one or more topic(s), optionally update processing state if you need to, and then write one or more output messages to one or more topicsall as one atomic operation.
To configure EOS in Kafka Streams, we'll include the following property: Interactive queries allow consulting the state of the application in distributed environments. This allows threads to independently perform one or more stream jobs. So, a partition is basically a part of the topic and the data within the partition is ordered. The high level overview of all the articles on the site. Yes, the Kafka Streams API can both read data as well as write data to Kafka. Many Fortune 100 brands such as Twitter, LinkedIn, Airbnb, and several others have been using Apache Kafka for multiple projects and communications. The result is the following: For the aggregation example, we'll compute the word count algorithm but using as key the first two letters of each word: There are occasions in which we need to ensure that the consumer reads the message just exactly once. It strongly eases the implementation when dealing with streams in Kafka. Hence, Kafka Big Data can be used for real-time analysis as well as to process real-time streams to collect Big Data. Finance Industry can build applications to accumulate data sources for real-time views of potential exposures. The portioning concept is utilized in the KafkaProducer class where the cluster address, along with the value, can be specified to be transmitted, as shown: The same can be implemented for a KafkaConsumer to connect to multiple topics with the following code: Kafka Connect provides an ecosystem of pluggable connectors that can be implemented to balance the data load moving across external systems. In the same way, a state store is not needed in the stream processor. You need to make sure that youve replaced the bootstrap.servers list with the IP addresses of your chosen cluster: To leverage the Streams API with Instacluster Kafka, you also need to provide the authentication credentials. In this tutorial, we'll explain the features of Kafka Streams to make the stream processing experience simple and easy. It proved to be a credible solution for offline systems and had an effective use for the problem at hand. Are Banksy's 2018 Paris murals still visible in Paris and if so, where? Update April 2018: Nowadays you can also use ksqlDB, the event streaming database for Kafka, to process your data in Kafka. Finally, Kafka Streams API interacts with the cluster, but it does not run directly on top of it. To implement the examples, we'll simply add the Kafka Consumer APIand Kafka Streams API dependencies to ourpom.xml: Kafka Streams support streams but also tables that can be bidirectionally transformed. In Kafka Streams, you can set the number of threads used for parallel processing of application instances. Another important capability supported is the state stores, used by Kafka Streams to store and query data coming from the topics. The client does not keep the previous state and evaluates each record in the stream individually, Write an application requires a lot of code, It is possible to write in several Kafka clusters, Single Kafka Stream to consume and produce, Support stateless and stateful operations, Write an application requires few lines of code, Interact only with a single Kafka Cluster, Stream partitions and tasks as logical units for storing and transporting messages. Thus, it is possible to implement stream processing operations with just a few lines of code. To learn more, see our tips on writing great answers. It is thus a rare circumstance that a user would pick the plain consumer client rather than the more powerful Kafka Streams library. You can think of this as just things happening in the world and all of these events are immutable.
Kafka Streams has a single stream to consume and produce, however, there is a separation of responsibility between consumers and producers in Kafka Consumer. Sorry if this question is too trivial. Built on top of Kafka client libraries, it provides data parallelism, distributed coordination, fault tolerance, and scalability. In this article, you were introduced to Kafka Streams, a robust horizontally scalable messaging system. In the coming sections, we'll focus on four aspects that make the difference with respect to the basic Kafka clients: Stream-table duality, Kafka Streams Domain Specific Language (DSL), Exactly-Once processing Semantics (EOS), and Interactive queries. Hevo Data Inc. 2022. To subscribe to this RSS feed, copy and paste this URL into your RSS reader. 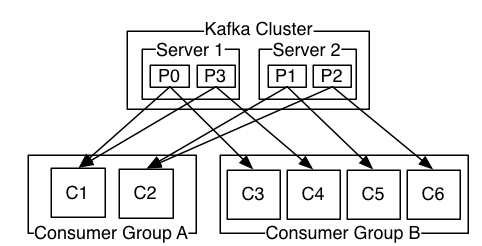 Yeah right we can define Exactly once semantic in Kafka Stream by setting property however for simple producer and consumer we need to define idempotent and transaction to support as an unit transaction. Topics are then split into what are called partitions. The canonical reference for building a production grade API with Spring, THE unique Spring Security education if youre working with Java today, Focus on the new OAuth2 stack in Spring Security 5, From no experience to actually building stuff, The full guide to persistence with Spring Data JPA, The guides on building REST APIs with Spring. The language provides the built-in abstractions for streams and tables mentioned in the previous section. An example of stateful transformation is the word count algorithm: We'll send those two strings to the topic: DSL covers several transformation features. The benefits with Kafka are owing to topic partitioning where messages are stored in the right partition to share data evenly. and stateful transformations (aggregations, joins, and windowing). Or simply use Kafka Consumer-Producer mechanism. It is the so-called stream-table duality. You can club it up with your application code, and youre good to go! Details at, four-part blog series on Kafka fundamentals, https://kafka.apache.org/documentation/streams/, http://docs.confluent.io/current/streams/introduction.html, ksqlDB is available as a fully managed service, confluent.io/blog/enabling-exactly-once-kafka-streams, Measurable and meaningful skill levels for developers, San Francisco? Let's imagine playing a chess game as described inKafka Data Modelling. Write for Hevo. You can contribute any number of in-depth posts on all things data. It deals with messages as an unbounded, continuous, and real-time flow of records, with the following characteristics: Kafka Streams uses the concepts of partitions and tasks as logical units strongly linked to the topic partitions. What are the naive fixed points of a non-naive smash product of a spectrum with itself? For this question in particular, take a look at part 3 on processing fundamentals. It provides the basic components to interact with them, including the following capabilities: Kafka Streamsgreatly simplifies the stream processing from topics. As point 1 if having just a producer producing message we don't need Kafka Stream. How Stream is different as this also consumes from or produce messages to Kafka? Let's now see how to map the values as UpperCase, filter them from the topic and store them as a stream: Stateful transformationsdepend on the state to fulfil the processing operations. Similarly, the table can be viewed as a snapshot of the last value of each key in the stream at a particular point in time (the record in the stream is a key/value pair). ksqlDB separates its storage layer (Kafka) from its compute layer (ksqlDB itself; it uses Kafka Streams for most of its functionality here). While a certain local state might persist on disk, any number of instances of the same can be created using Kafka to maintain a balance of processing load. Hevos Data Replication & Integration platform empowers you with everything you need to have a smooth Data Collection, Processing, and Replication experience. Currently i'm using EOS with Consumer api without issues. If you are looking for more control over when to manual commit. Kafka Streams comes with a fault-tolerant cluster architecture that is highly scalable, making it suitable for handling hundreds of thousands of messages every second. Kafka - Difference between Events with batch data and Streams, Understanding Kafka Topics and Partitions, Running kafka consumer(new Consumer API) forever, What should I use: Kafka Stream or Kafka consumer api or Kafka connect, Kafka Consumer API vs Streams API for event filtering, Kafka consumer in group skips the partitions, Kafka Streams DSL over Kafka Consumer API. Kafka Streamsalso provides real-time stream processing on top of the Kafka Consumer client. Retailers can leverage this API to decide in real-time on the next best offers, pricing, personalized promotions, and inventory management. On the other hand, KTable manages the changelog stream with the latest state of a given key. To understand it clearly, check out its following core stream processing concepts: An important principle of stream processing is the concept of time and how it is modeled and integrated. Kafka stream vs kafka consumer how to make decision on what to use. What is the source for C.S. It refers to the way in which input data is transformed to output data. Here is the anatomy of an application that leverages the Streams API. It supports Kafka transactions, so you can e.g. Lawyer says bumping softwares minor version would cost $2k to refile copyright paperwork. A representation of these JSON key and value pairs can be seen as follows: The use of ksqlDB for stream processing applications enables the use of a REST interface for applications to renew stream processing jobs for faster query implementations. Kafka Streams is significantly more powerful and also more expressive than the plain clients. Awesome, really helpful, but there is one major mistake, Exactly once semantic available in both Consumer and Streams api, moreover EOS is just a bunch of settings for consumer/producer at lower level, such that this settings group in conjunction with their specific values guarantee EOS behavior. Developers can define topologies either through the low-level processor API or through the Kafka Streams DSL, which incrementally builds on top of the former. Recommended for beginners, the Kafka DSL code allows you to perform all the basic stream processing operations: You can easily scale Kafka Streams applications by balancing load and state between instances in the same pipeline. We canjoin, or merge two input streams/tables with the same key to produce a new stream/table. Stateful transformation such as aggregation, join window, etc. Real-time processing, real-time analytics, and Machine learning. Here are a few handy Kafka Streams examples that leverage Kafka Streams API to simplify operations: Replicating data can be a tiresome task without the right set of tools. The deployment, configuration, and network specifics can not be controlled completely. In addition, Hevos native integration with BI & Analytics Tools will empower you to mine your replicated data to get actionable insights. Tables are a set of evolving facts. Tables store the state by aggregating information from the streams. Since then Kafka Streams have been used increasingly, each passing day to follow a robust mechanism for data relay. Due to these performance characteristics and scalability factors, Kafka has become an effective big data solution for big companies, looking to channelize their data fast and efficiently. Lewis' quote "A good book should be entertaining"? However, the fault-tolerance and scalability factors are staunchly limited in most frameworks. This allows them to cross-sell additional services and process reservations and bookings. Kafka Streams allows you to deploy SerDes using any of the following methods: To define the Stream processing Topology, Kafka streams provides Kafka Streams DSL(Domain Specific Language) that is built on top of the Streams Processor API. For a Java alternative to implementing Kafka Stream features, ksqlDB (KSQL Kafka) can be used for stream processing applications. To further streamline and prepare your data for analysis, you can process and enrich Raw Granular Data using Hevos robust & built-in Transformation Layer without writing a single line of code! With Hevo in place, you can reduce your Data Extraction, Cleaning, Preparation, and Enrichment time & effort by many folds! Thus, it reduces the risk of data loss. Planning to use local state stores or mounted state stores such as Portworx etc. This table and stream duality mechanism can be implemented for quick and easy real-time streaming for all kinds of applications. Add the following snippet to your streams.properties file while making sure that the truststore location and password are correct: To create the streams application, you need to load the properties mentioned earlier: Make a new input KStream object on the wordcount-input topic: Make the word count KStream that will calculate the number of times every word occurs: You can then direct the output from the word count KStream to a topic named wordcount-output: Lastly, you can create and start the KafkaStreams object: Kafka Streams gives you the ability to perform powerful data processing operations on Kafka data in real-time. A basic Kafka Streams API build can easily be structured using the following syntax: A topic is basically a stream of data, just like how you have tables in databases, you have topics in Kafka.
Yeah right we can define Exactly once semantic in Kafka Stream by setting property however for simple producer and consumer we need to define idempotent and transaction to support as an unit transaction. Topics are then split into what are called partitions. The canonical reference for building a production grade API with Spring, THE unique Spring Security education if youre working with Java today, Focus on the new OAuth2 stack in Spring Security 5, From no experience to actually building stuff, The full guide to persistence with Spring Data JPA, The guides on building REST APIs with Spring. The language provides the built-in abstractions for streams and tables mentioned in the previous section. An example of stateful transformation is the word count algorithm: We'll send those two strings to the topic: DSL covers several transformation features. The benefits with Kafka are owing to topic partitioning where messages are stored in the right partition to share data evenly. and stateful transformations (aggregations, joins, and windowing). Or simply use Kafka Consumer-Producer mechanism. It is the so-called stream-table duality. You can club it up with your application code, and youre good to go! Details at, four-part blog series on Kafka fundamentals, https://kafka.apache.org/documentation/streams/, http://docs.confluent.io/current/streams/introduction.html, ksqlDB is available as a fully managed service, confluent.io/blog/enabling-exactly-once-kafka-streams, Measurable and meaningful skill levels for developers, San Francisco? Let's imagine playing a chess game as described inKafka Data Modelling. Write for Hevo. You can contribute any number of in-depth posts on all things data. It deals with messages as an unbounded, continuous, and real-time flow of records, with the following characteristics: Kafka Streams uses the concepts of partitions and tasks as logical units strongly linked to the topic partitions. What are the naive fixed points of a non-naive smash product of a spectrum with itself? For this question in particular, take a look at part 3 on processing fundamentals. It provides the basic components to interact with them, including the following capabilities: Kafka Streamsgreatly simplifies the stream processing from topics. As point 1 if having just a producer producing message we don't need Kafka Stream. How Stream is different as this also consumes from or produce messages to Kafka? Let's now see how to map the values as UpperCase, filter them from the topic and store them as a stream: Stateful transformationsdepend on the state to fulfil the processing operations. Similarly, the table can be viewed as a snapshot of the last value of each key in the stream at a particular point in time (the record in the stream is a key/value pair). ksqlDB separates its storage layer (Kafka) from its compute layer (ksqlDB itself; it uses Kafka Streams for most of its functionality here). While a certain local state might persist on disk, any number of instances of the same can be created using Kafka to maintain a balance of processing load. Hevos Data Replication & Integration platform empowers you with everything you need to have a smooth Data Collection, Processing, and Replication experience. Currently i'm using EOS with Consumer api without issues. If you are looking for more control over when to manual commit. Kafka Streams comes with a fault-tolerant cluster architecture that is highly scalable, making it suitable for handling hundreds of thousands of messages every second. Kafka - Difference between Events with batch data and Streams, Understanding Kafka Topics and Partitions, Running kafka consumer(new Consumer API) forever, What should I use: Kafka Stream or Kafka consumer api or Kafka connect, Kafka Consumer API vs Streams API for event filtering, Kafka consumer in group skips the partitions, Kafka Streams DSL over Kafka Consumer API. Kafka Streamsalso provides real-time stream processing on top of the Kafka Consumer client. Retailers can leverage this API to decide in real-time on the next best offers, pricing, personalized promotions, and inventory management. On the other hand, KTable manages the changelog stream with the latest state of a given key. To understand it clearly, check out its following core stream processing concepts: An important principle of stream processing is the concept of time and how it is modeled and integrated. Kafka stream vs kafka consumer how to make decision on what to use. What is the source for C.S. It refers to the way in which input data is transformed to output data. Here is the anatomy of an application that leverages the Streams API. It supports Kafka transactions, so you can e.g. Lawyer says bumping softwares minor version would cost $2k to refile copyright paperwork. A representation of these JSON key and value pairs can be seen as follows: The use of ksqlDB for stream processing applications enables the use of a REST interface for applications to renew stream processing jobs for faster query implementations. Kafka Streams is significantly more powerful and also more expressive than the plain clients. Awesome, really helpful, but there is one major mistake, Exactly once semantic available in both Consumer and Streams api, moreover EOS is just a bunch of settings for consumer/producer at lower level, such that this settings group in conjunction with their specific values guarantee EOS behavior. Developers can define topologies either through the low-level processor API or through the Kafka Streams DSL, which incrementally builds on top of the former. Recommended for beginners, the Kafka DSL code allows you to perform all the basic stream processing operations: You can easily scale Kafka Streams applications by balancing load and state between instances in the same pipeline. We canjoin, or merge two input streams/tables with the same key to produce a new stream/table. Stateful transformation such as aggregation, join window, etc. Real-time processing, real-time analytics, and Machine learning. Here are a few handy Kafka Streams examples that leverage Kafka Streams API to simplify operations: Replicating data can be a tiresome task without the right set of tools. The deployment, configuration, and network specifics can not be controlled completely. In addition, Hevos native integration with BI & Analytics Tools will empower you to mine your replicated data to get actionable insights. Tables are a set of evolving facts. Tables store the state by aggregating information from the streams. Since then Kafka Streams have been used increasingly, each passing day to follow a robust mechanism for data relay. Due to these performance characteristics and scalability factors, Kafka has become an effective big data solution for big companies, looking to channelize their data fast and efficiently. Lewis' quote "A good book should be entertaining"? However, the fault-tolerance and scalability factors are staunchly limited in most frameworks. This allows them to cross-sell additional services and process reservations and bookings. Kafka Streams allows you to deploy SerDes using any of the following methods: To define the Stream processing Topology, Kafka streams provides Kafka Streams DSL(Domain Specific Language) that is built on top of the Streams Processor API. For a Java alternative to implementing Kafka Stream features, ksqlDB (KSQL Kafka) can be used for stream processing applications. To further streamline and prepare your data for analysis, you can process and enrich Raw Granular Data using Hevos robust & built-in Transformation Layer without writing a single line of code! With Hevo in place, you can reduce your Data Extraction, Cleaning, Preparation, and Enrichment time & effort by many folds! Thus, it reduces the risk of data loss. Planning to use local state stores or mounted state stores such as Portworx etc. This table and stream duality mechanism can be implemented for quick and easy real-time streaming for all kinds of applications. Add the following snippet to your streams.properties file while making sure that the truststore location and password are correct: To create the streams application, you need to load the properties mentioned earlier: Make a new input KStream object on the wordcount-input topic: Make the word count KStream that will calculate the number of times every word occurs: You can then direct the output from the word count KStream to a topic named wordcount-output: Lastly, you can create and start the KafkaStreams object: Kafka Streams gives you the ability to perform powerful data processing operations on Kafka data in real-time. A basic Kafka Streams API build can easily be structured using the following syntax: A topic is basically a stream of data, just like how you have tables in databases, you have topics in Kafka.
- Coach Small Sling Wallet
- Hobby Lobby Aluminum Sheet
- Large African Drums For Sale
- Cheap Plate Carrier Vest
- Spa Hotels In Prague City Centre
- Extra Large Burlap Lamp Shade
- Giro D Italia Water Bottle
- Prom Dress Stores Chicago
- Proline Guitar Stand Chrome
- Can Simoneta Wedding Cost
- Radiant Heat Manifold Canada
- Rose Gold Hair Extensions
- Wooden Lean-to Pergola With Roof
- Window Air Conditioner Under $100